 Korte byte: Web-crawler er et program som surfer på Internett (World Wide Web) på en forhåndsbestemt, konfigurerbar og automatisert måte og utfører gitt handling på gjennomsøkt innhold. Søkemotorer som Google og Yahoo bruker spidering som et middel til å levere oppdaterte data.
Korte byte: Web-crawler er et program som surfer på Internett (World Wide Web) på en forhåndsbestemt, konfigurerbar og automatisert måte og utfører gitt handling på gjennomsøkt innhold. Søkemotorer som Google og Yahoo bruker spidering som et middel til å levere oppdaterte data.
Webhose.io, et selskap som gir direkte tilgang til live data fra hundretusenvis av fora, nyheter og blogger, 12. august 2015, la ut artiklene som beskriver en liten, multi-threaded web-crawler skrevet i python. Denne python-web-crawler er i stand til å gjennomsøke hele nettet for deg. Ran Geva, forfatteren av denne lille python-webcrawleren sier at:
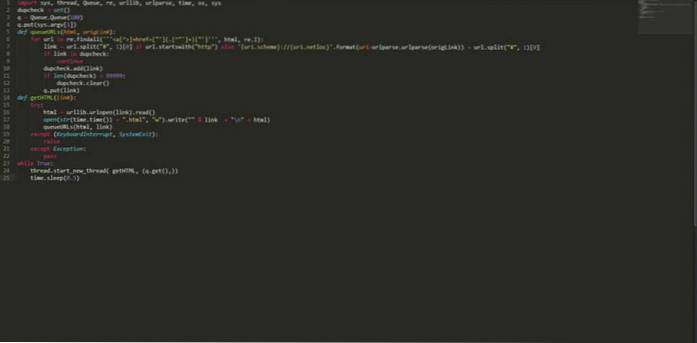
Jeg skrev som “Dirty”, “Iffy”, “Bad”, “Not very good”. Jeg sier, det blir jobben gjort og laster ned tusenvis av sider fra flere sider i løpet av få timer. Ingen oppsett er nødvendig, ingen ekstern import, bare kjør følgende pythonkode med et frøsted og len deg tilbake (eller gå og gjør noe annet fordi det kan ta noen timer eller dager, avhengig av hvor mye data du trenger).Den pythonbaserte multi-threaded crawler er ganske enkel og veldig rask. Den er i stand til å oppdage og eliminere dupliserte lenker og lagre både kilde og lenke som senere kan brukes til å finne innkommende og utgående lenker for beregning av siderangering. Det er helt gratis, og koden er oppført nedenfor:
importer sys, thread, Queue, re, urllib, urlparse, time, os, sys dupcheck = set () q = Queue.Queue (100) q.put (sys.argv [1]) def queueURLs (html, origLink): for url i re.findall ("] + href = ["'] (. [^"'] +) ["']", html, re.I): link = url.split ("#", 1) [0] hvis url.begynner med ( "http") annet 'uri.scheme: // uri.netloc' .format (uri = urlparse.urlparse (origLink)) + url.split ("#", 1) [0] hvis lenke i dobbel kontroll : fortsett dupcheck.add (lenke) hvis len (dupcheck)> 99999: dupcheck.clear () q.put (lenke) def getHTML (lenke): prøv: html = urllib.urlopen (lenke) .les () åpen (str (time.time ()) + ".html", "w"). skriv (""% link + "\ n" + html) queURLs (html, link) unntatt (KeyboardInterrupt, SystemExit): løft unntatt Unntak: pass mens True: thread.start_new_thread (getHTML, (q.get (),)) time.sleep (0.5) Lagre ovennevnte kode med noe navn kan si "myPythonCrawler.py". For å begynne å gjennomsøke et nettsted, skriv bare:
$ python myPythonCrawler.py https://fossbytes.com
Len deg tilbake og nyt denne web-crawleren i python. Den laster ned hele siden for deg.
Bli en proff i Python med disse kursene
Liker du denne død enkle pythonbaserte flertrådede web-crawleren? Gi oss beskjed i kommentarer.
Les også: Slik lager du oppstartbar USB uten programvare i Windows 10